Estimation des rendements des petits producteurs de maïs en Éthiopie grâce aux satellites et à l'apprentissage automatique

Le suivi exact et précis de la production agricole dans les pays en développement est un outil crucial pour la bonne allocation des fonds et services publics, la lutte contre la pauvreté et l'augmentation durable des rendements pour nourrir des populations croissantes. Mais l'estimation précise du rendement des cultures est particulièrement difficile en Afrique subsaharienne (ASS), où prédominent les petites exploitations hétérogènes, ce qui rend la collecte des données coûteuse et souvent sujette à des biais systémiques.
L'imagerie satellitaire est un outil de plus en plus utile pour estimer le rendement des cultures à une échelle fine, au niveau des parcelles, sur de vastes zones telles que des régions ou des pays. Une équipe de recherche de l'IFPRI, utilisant l'Éthiopie comme étude de cas, a évalué diverses approches d'apprentissage automatique pour estimer les rendements du maïs en temps quasi réel à l'aide d'images satellite à haute résolution spatiale. Les résultats suggèrent qu'il est possible d'utiliser des algorithmes d'apprentissage automatique (en particulier des réseaux neuronaux) formés à partir d'images satellite et de données de terrain pour informer les politiques nationales à l'aide d'estimations granulaires du rendement des cultures.
Cette approche est devenue réalisable pour les chercheurs publics des pays en développement car les éléments suivants sont devenus accessibles au public ces dernières années : L'imagerie satellitaire granulaire dans l'espace et dans le temps, des serveurs puissants en termes de calcul et des moteurs d'apprentissage automatique "prêts à l'emploi". Toutes les recherches ont été effectuées en code dynamique à l'aide de Google Earth Engine (GEE) et de TensorFlow pour une reproduction simple dans d'autres contextes. Les questions de recherche incluaient :
- Quelles variables sont les meilleurs prédicteurs de la production et à quelle période de l'année ?
- Quel modèle d'estimation ou quelle approche d'apprentissage automatique est le plus précis ?
- Dans quelle mesure un modèle est-il transférable à d'autres contextes spatiaux et temporels ?
Sept modèles d'apprentissage automatique ont été évalués en utilisant 13 combinaisons de quatre types de prédicteurs : Sept bandes spectrales de l'imagerie du satellite d'observation de la terre Sentinel-2 ; les indices de végétation NDVI (indice de différence de végétation normalisé) et ICG (indice de chlorophylle verte) ; des mesures climatiques ; et des mesures de la qualité du sol.
Les indices de végétation, qui évaluent la réflectivité infrarouge d'une végétation saine, sont les principaux prédicteurs du rendement du maïs. Il est important de noter que l'inclusion d'un plus grand nombre de variables n'améliore pas nécessairement la précision. En utilisant une mesure commune de la capacité prédictive d'un modèle (R-carré) pour comparer les spécifications, un modèle d'estimation Random Forest avec des indices de végétation, des mesures climatiques et des indicateurs de qualité du sol donne un R-carré de 0,54 ; l'ajout de toutes les mesures brutes d'imagerie satellitaire a réduit le R-carré à 0,15.
Étant donné la prévalence de la couverture nuageuse dans les tropiques, qui peut dégrader l'intégrité de l'imagerie satellitaire, les chercheurs ont utilisé un algorithme de lissage (Savitsky-Golay) pour réduire le bruit dans les indices de végétation. En examinant à quel moment de l'année les mesures devraient être effectuées pour une estimation optimale du rendement des cultures, ils ont trouvé que les données sur les précipitations et l'humidité de septembre (début de la saison de croissance) étaient les plus essentielles, tandis que les données les plus essentielles sur la température maximale étaient celles de novembre (fin de la saison de croissance).
En incluant la combinaison optimale de paramètres (indices de végétation, mesures climatiques et indicateurs de qualité du sol), chaque algorithme d'apprentissage automatique a été évalué en divisant les données en un ensemble d'apprentissage (utilisé pour former le modèle) et un ensemble de validation (utilisé pour tester la précision du modèle). L'approche la plus précise (avec un R-carré de 0,62 dans l'ensemble de validation) était un réseau neuronal, modelé sur le comportement des neurones du cerveau humain pour comprendre les relations entre les entrées de données. Une représentation visuelle de la précision du modèle peut être observée dans la figure ci-dessous pour l'ensemble de formation et de validation, où les lignes grises fines indiquent la tendance de prédiction idéale et les lignes colorées indiquent la tendance de prédiction réelle. Bien que la ligne verte (indiquant la tendance de prédiction dans l'ensemble de validation) semble précise, une mise en garde importante à noter est que ce modèle sur-prévoit le rendement pour les agriculteurs les moins productifs.
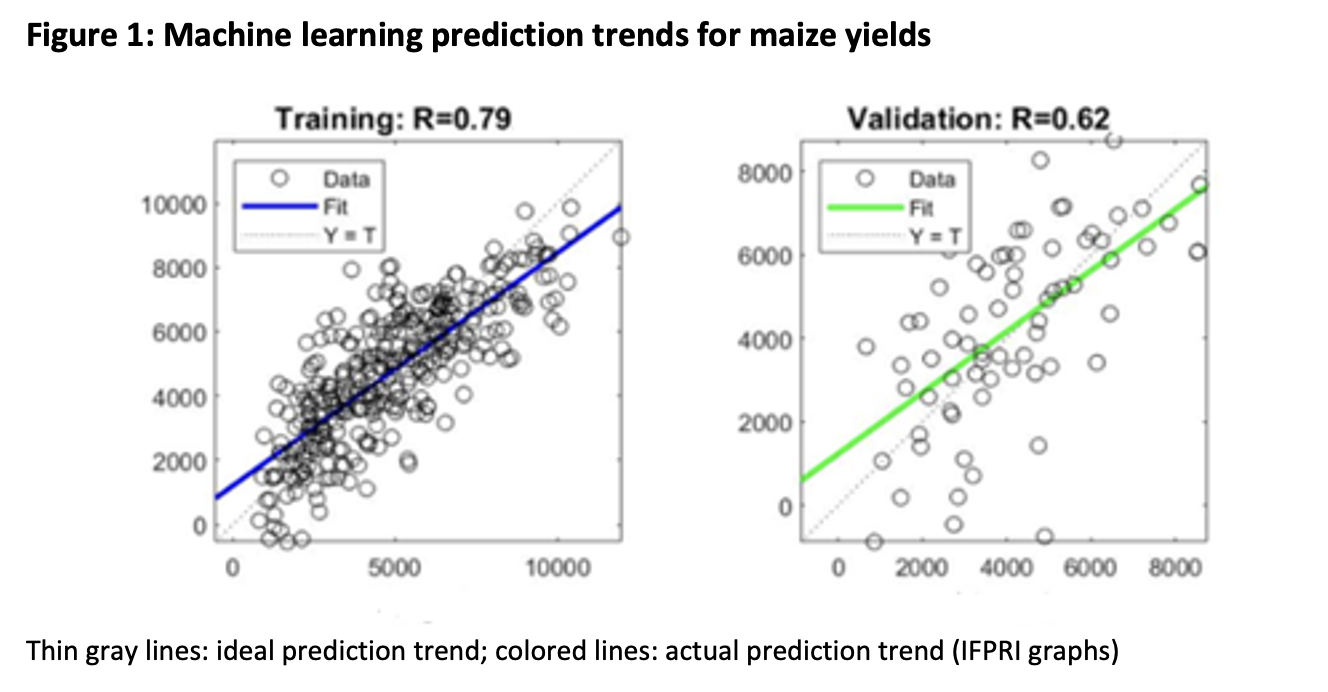
Il est important de noter que ce modèle a exploré la transférabilité potentielle de la prédiction du rendement en cours de saison. D'autres études peuvent évaluer les compromis de précision spécifiques du transfert de ce modèle à différentes années. Une question de recherche essentielle pour l'avenir concerne la transférabilité de ce modèle à travers les zones géographiques. Par exemple, dans quelle mesure un modèle formé sur des données éthiopiennes peut-il être précis pour estimer le rendement des cultures au Kenya ?
Étant donné la prévalence de l'agriculture dans les communautés les plus pauvres du monde, l'élaboration de politiques agricoles bien informées est essentielle au développement économique. Des prévisions de rendement des cultures abordables, exactes et précises, réalisées sur de vastes régions, peuvent optimiser les politiques et les décisions d'allocation dans les pays en développement. Les algorithmes d'apprentissage automatique utilisant l'imagerie satellitaire publique peuvent être un outil puissant pour comprendre de manière efficace et effective la productivité agricole dans des régions particulières.
Zhe Guo est coordinateur SIG senior au sein de la division Environnement et technologies de production (EPDT) de l'IFPRI ; Billy Babis est chercheur en télédétection et candidat au doctorat à l'université de Tufts.