Estimating smallholder maize yields in Ethiopia with satellites and machine learning

Accurate and precise monitoring of agricultural output in developing countries is a crucial tool for the proper allocation of public funds and services, in addressing poverty, and in sustainably increasing yields to feed growing populations. But accurate crop yield estimation is particularly challenging in sub-Saharan Africa (SSA), where heterogeneous smallholder farms predominate, making data collection expensive and often subject to systemic bias.
Satellite imagery is an increasingly helpful tool for estimating crop yields at fine, plot-level scales over large areas such as regions or countries. A research team at IFPRI, using Ethiopia as a case study, evaluated various machine learning approaches to estimating maize yields near-real-time using high spatial resolution satellite imagery. The results suggest the feasibility of using machine learning algorithms (especially neural networks) trained on satellite imagery and ground-truth data to inform national policies with granular crop-yield estimations.
This approach has become feasible for public researchers in developing countries because the following have become publicly available in recent years: Spatially and temporally granular satellite imagery, computationally powerful servers, and ”out of the box” machine learning engines. All of the research was performed in dynamic code using Google Earth Engine (GEE) and TensorFlow for simple replication in other contexts. Research questions included:
- Which variables are the best predictors of output and during what time of year?
- Which estimation model or machine learning approach is most accurate?
- How transferable is one model to other spatial and temporal settings?
Seven machine learning models were evaluated using 13 combinations of four types of predictors: Seven spectral bands of Sentinel-2 earth observation satellite imagery; the vegetation indices NDVI (normalized difference vegetation index) and GCI (green chlorophyll index); climate measurements; and soil quality measurements.
The most important predictors of maize yield were the vegetation indices, which gauge the infrared reflectivity of healthy vegetation. Importantly, including more variables does not necessarily improve accuracy. Employing a common measurement of a model’s predictive ability (R-squared) to compare specifications, a Random Forest estimation model with vegetation indices, climate measurements, and soil quality indicators yields an R-squared of 0.54; adding all raw satellite imagery measurements decreased the R-squared to 0.15.
Given the prevalence of cloud coverage in the tropics that can degrade the integrity of satellite imagery, the researchers employed a smoothing algorithm (Savitsky-Golay) to reduce noise in the vegetation indices. In exploring what time of year measurements should be made for optimal crop-yield estimation, they found precipitation and moisture data from September (early growing season) most essential, while the most essential data on maximum temperature was from November (end of growing season).
Including the optimal combination of parameters (vegetation indices, climate measurements, and soil quality indicators), each machine learning algorithm was assessed by dividing the data into a training set (used to train the model) and a validation set (used to test the model’s accuracy). The most accurate (with R-squared of 0.62 in validation set) was a neural network approach, modeled on the behavior of neurons in the human brain to understand relationships between data inputs. A visual depiction of the model’s accuracy can be seen in the figure below for both the training and validation set, where the thin gray lines indicate the ideal prediction trend and the colored lines indicate the actual prediction trend. While the green line (indicating the prediction trend in the validation set) appears accurate, an important caveat to note is that this model over-predicts yield for the least productive farmers.
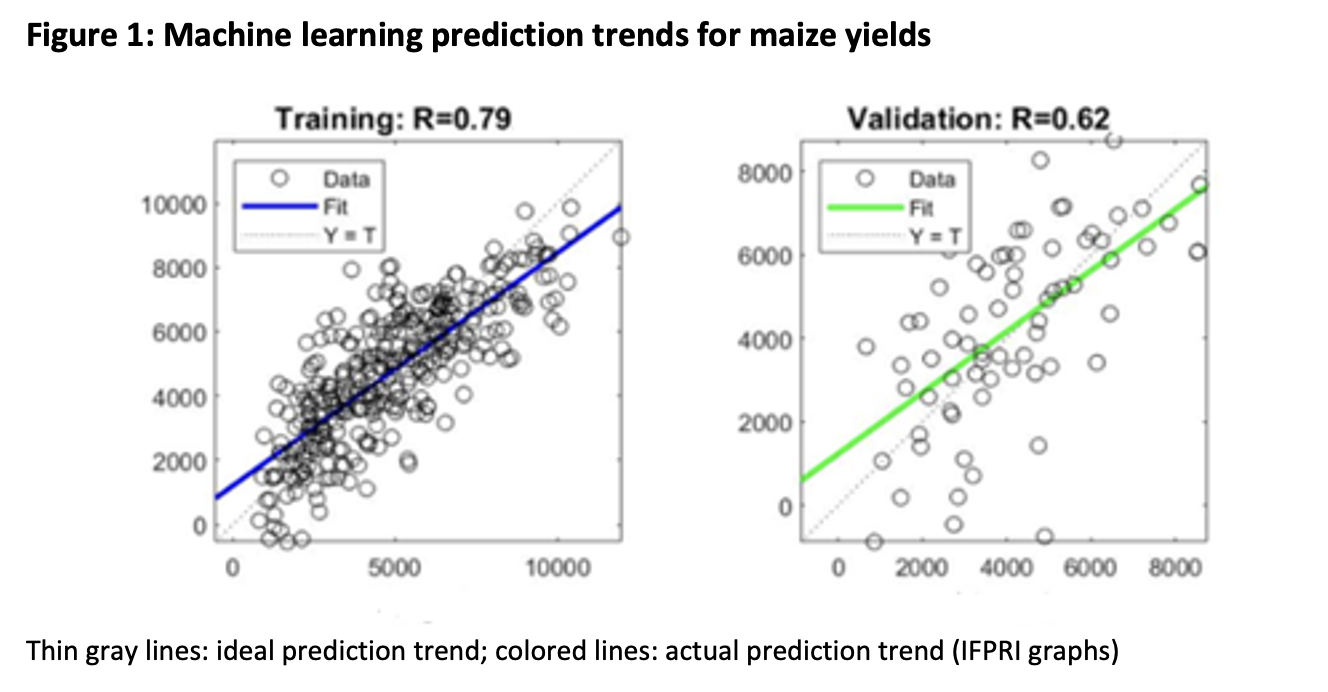
Importantly, this model explored the potential transferability in predicting in-season yield. Further studies can evaluate the specific accuracy trade-offs of transferring this model to different years. An essential research question moving forward regards the transferability of this model across geographic areas. For example, how accurate can a model trained on Ethiopian data be in estimating crop yield in Kenya?
Given the prevalence of agriculture among the world’s poorest communities, fully informed agricultural policymaking is essential for economic development. Affordable, accurate, and precise crop yield prediction performed across large regions can optimize policy and allocation decisions in developing countries. Machine learning algorithms employing publicly available satellite imagery can be a powerful tool in efficiently and effectively understanding agricultural productivity in particular regions.
Zhe Guo is a Senior GIS Coordinator with IFPRI's Environment and Production Technology Division (EPDT); Billy Babis is a remote sensing researcher and PhD candidate at Tufts University.